金山云
文档中心
MapReduce
准备
1.您已经创建KMR集群以及相关其他服务,KMR集群默认安装Hadoop,详情参考 集群创建
2.您已经使用SSH连接到集群,详情参考 使用SSH访问集群,或者已经开通云主机作为客户端节点,以下操作均在集群主节点进行。
3.如需使用KS3存储,请开通KS3服务,如何使用KS3,请参考 KS3文档
MapReduce作业
以WordCount为例,介绍如何使用Hadoop实现单词统计功能
程序准备
以下代码来源于Hadoop官网 Wrodcount实例代码
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
设置JDK和Hadoop环境变量,假设java安装路径为/usr/java/jdk1.7.0_51
export JAVA_HOME=/usr/java/jdk1.7.0_51
export PATH=${JAVA_HOME}/bin:${PATH}
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar 编译程序
mkdir wordcount_classes
hadoop com.sun.tools.javac.Main -d wordcount_classes/ WordCount.java
jar cvf wordcount.jar -C wordcount_classes . 这样就得到了wordcount.jar
作业输入输出
hadoop作业的输入和输出文件,可以放在HDFS上,也可以选择放在KS3上。
使用HDFS
将输入文件放到HDFS上,假设输入文件为TWILIGHT.txt
hadoop dfs -mkdir -p /user/hadoop/examples/input
hadoop dfs -put TWILIGHT.txt /user/hadoop/examples/input 使用KS3
- 可以在KS3控制台上直接创建目录、上传本地文件

- 也可以用命令行将jar包和输入文件放到KS3上
hadoop dfs -mkdir -p ks3://kmrtest9/wordcount/lib
hadoop dfs -mkdir -p ks3://kmrtest9/wordcount/input
hadoop dfs -put wordcount.jar ks3://kmrtest9/wordcount/lib
hadoop dfs -put TWILIGHT.txt ks3://kmrtest9/wordcount/input作业提交
命令行提交
输入输出在HDFS上:
hadoop jar wordcount.jar WordCount /user/hadoop/examples/input/ /user/hadoop/examples/output输入输出在KS3上:
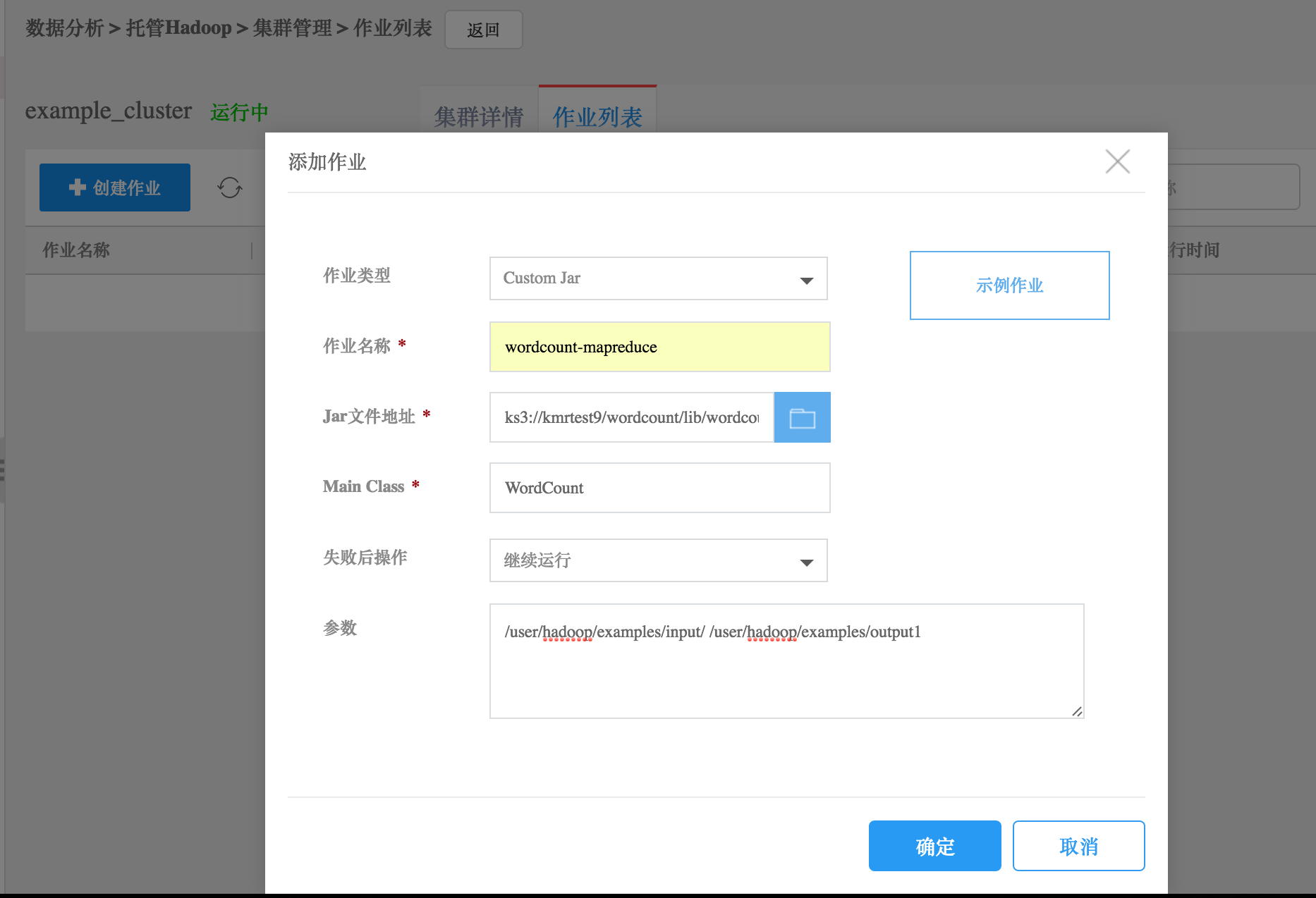
hadoop jar wordcount.jar WordCount ks3://kmrtest9/wordcount/input/ ks3://kmrtest9/wordcount/outputKMR控制台提交
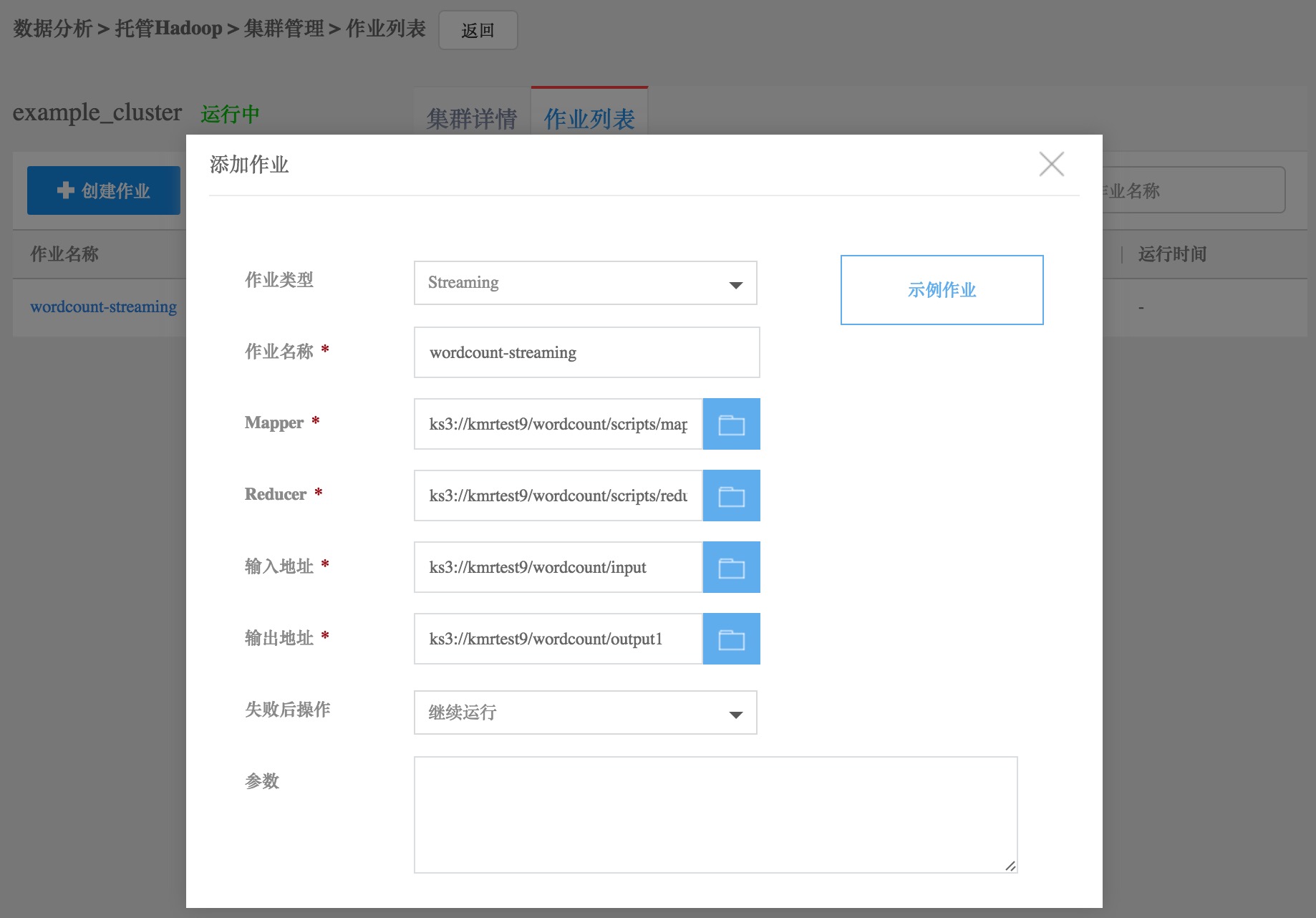
对于临时集群,可以在控制台提交作业。
在作业列表标签页中,点击“创建作业”按钮,添加作业。注意:需要将Jar包放到ks3上。
Hadoop Streaming
Hadoop Streaming允许用户使用可执行的命令或者脚本作为mapper和reducer。以下用几个示例说明Hadoop Streaming如何使用。 详细可参考Hadoop官网Hadoop Streaming
使用shell命令作为mapper和reducer
hadoop jar /opt/hadoop/share/hadoop/tools/lib/hadoop-streaming-*.jar -input /user/hadoop/examples/input/ -output /user/hadoop/examples/output1 -mapper /bin/cat -reducer /usr/bin/wc使用python脚本作为mapper和reducer
mapper.py
#!/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print "%s\t%s" % (word, 1)reducer.py
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print "%s\t%s" % (current_word, current_count)
current_count = count
current_word = word
if word == current_word:
print "%s\t%s" % (current_word, current_count)命令行执行streaming作业
chmod +x mapper.py
chmod +x reducer.py
hadoop jar /opt/hadoop/share/hadoop/tools/lib/hadoop-streaming-*.jar -input /user/hadoop/examples/input/ -output /user/hadoop/examples/output2 -mapper mapper.py -reducer reducer.py -file mapper.py -file reducer.py 对于临时集群,可以在KMR控制台提交作业