文档中心
产品概述
大数据是关于收集,储存,处理和展现大规模数据的技术,它可以帮助企业从这些数据中提取知识,并且做出更好的商业决策,所有的这些工作必须在有限的时间内尽快完成。大数据处理的一个最主要挑战就是数据分析平台的管理,包括了安装和操作管理,对于多种工作负载动态的分配数据处理能力,以及从多个来源收集数据进行整体分析。
KMR(Kingsoft MapReduce)是一个可伸缩的通用数据计算和分析平台,它以Apache Hadoop 和Apache Spark两大数据计算框架为基础,通过自动调度弹性计算服务(KEC),帮助您快速构建分布式数据分析系统。
KMR提供了强大的扩展能力和弹性伸缩能力,消除了Hadoop安装部署成本和管理复杂性,可以使您不必关注基础架构管理,而更加专注数据分析处理本身,任何的开发者或者公司只需要较低的成本就可以进行大规模的数据分析和处理工作。
KMR集群由主节点(Master Node)和若干核心节点(Core Node)、任务节点(Task Node)组成。
主节点:主要用于集群管理,运行hadoop集群中的管理进程,如namenode、resource manager、jobhistory等。此外,它还会跟踪每个计算作业的执行状态,监控实例的运行状况,为您提供集群访问的入口。1个KMR集群只有1个主节点
核心节点:主要用于执行各项集群计算作业,同时也是分布式文件系统(HDFS)的数据存储节点,对应于hadoop集群中的slave节点。一个KMR集群可以有2至多个核心节点。
任务节点:非必须节点类型,可在集群创建完成后添加或者删除,用于执行各项集群计算作业,不作为分布式文件系统(HDFS)的数据存储节点,相对于核心节点,具有更大的灵活性
KMR提供了多种节点配置(请参考KMR产品定价与选购),您可根据自身需求选取,并在需要时动态的增加或者减少节点数量。
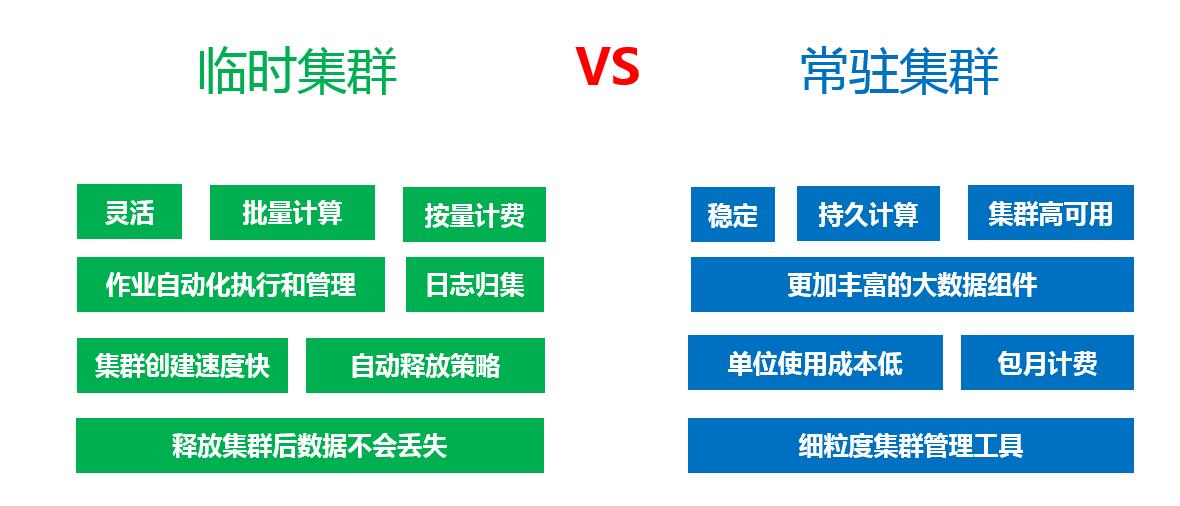
针对不同的数据处理场景KMR提供了2种不同的集群类型:
临时集群:主要用于Mapreduce等批量计算型作业,它灵活、创建速度快,可以根据需求随时启停和自动释放,基于KS3的数据存储和日志归集功能更可以使您在集群释放后仍然可以访问计算结果和集群日志。
常驻集群:主要用于海量数据存储,在线查询和流式计算或者更为复杂的场景,它具有多个层面的高可用设计可以保证集群不间断的对外提供服务,常驻集群提供了细粒度的通用集群管理工具ambari,可以帮助您更加高效的进行集群监控和调优等工作。