文档中心
作业创建指南
KMR控制台支持Custom Jar , Streaming, Hive, Pig, Spark等作业类型,您也可以使用KMR OpenAPI来为集群创建作业,详见 《KMR API 参考手册》
1.添加Custom JAR作业
您可以编写 Java 应用程序,生成 JAR 文件,然后将 JAR 文件上传到集群本地HDFS或者KS3中来处理数据。当执行此操作时,JAR 文件必须包含适用于 Map-Reduce 功能的实现。
1.在KMR集群创建时或者创建完成后打开添加作业页面,前置步骤请参考集群创建和集群操作中的作业详情部分
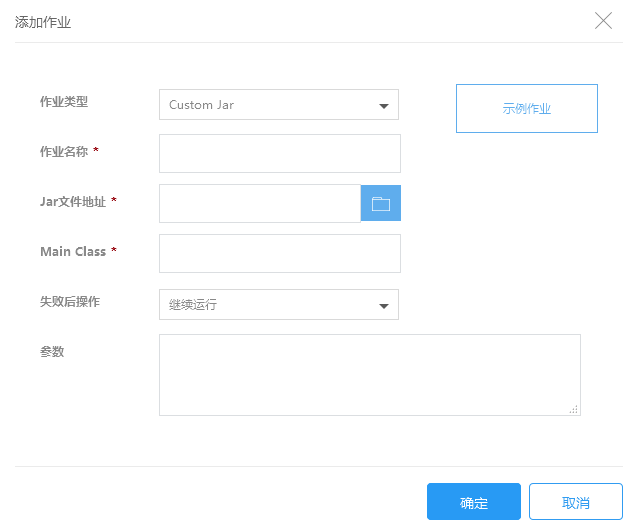
2.在添加作业页面填写作业信息,点击确定提交:
| 字段 | 操作 |
|---|---|
| 作业类型 | 选择需要执行的作业类型,这里请选择Custom Jar |
| 作业名称 | 输入作业名称,长度最多25个字符 |
| JAR文件地址 | 输入JAR包的存储路径,如使用KS3存储它们,该路径的形式为: ks3://BucketName/path/jar |
| MainClass | 指定主程序的类名 |
| 失败后操作 | 当作业执行失败后,集群可以根据这里的设置自动执行一些操作 继续:作业执行失败后,继续执行下一个作业。 取消作业并等待:作业执行失败后,取消集群中已提交的作业,集群进入等待状态,直到提交下一个作业。 销毁集群:作业运行失败后,销毁集群。 该选项的结果不会受到“集群释放保护”功能影响 |
| 参数 | 您可以为作业输入一些参数,这些参数会不做任何修改的传给MainClass中的main函数。输入参数时,只需要输入参数本身字符串即可,用空格分隔,无需参数转义和url encode。 |
3.如果您是在创建集群阶段添加作业,点击“下一步”,跳转到确认订单页面,提交订单后,添加的作业会在集群创建完成后开始执行。
4.如果您是对已创建的集群添加作业,作业提交后立即开始执行。
2.添加Streaming作业
Hadoop Streaming 是 Hadoop 附带的一种实用功能,可让您使用非 Java 语言开发 MapReduce 可执行文件。您可以在控制台上创建streaming作业,也可以像运行标准 JAR 文件一样,通过KMR API来运行它。
有关hadoop streaming,请参考
http://hadoop.apache.org/docs/r2.6.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/HadoopStreaming.html
1.在KMR集群创建时或者创建完成后打开添加作业页面,前置步骤请参考 集群创建和集群操作中的作业详情部分
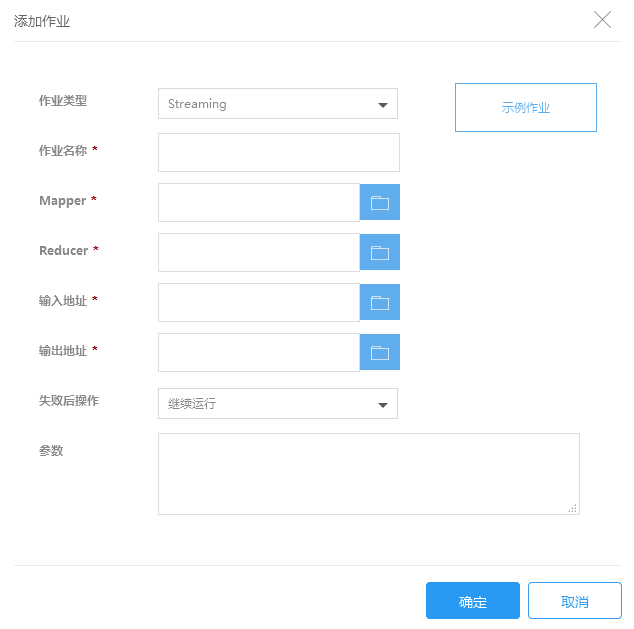
2.在添加作业页面填写作业信息,点击确定提交:
| 字段 | 操作 |
|---|---|
| 作业类型 | 选择需要执行的作业类型,这里请选择Streaming |
| 作业名称 | 输入作业名称,长度最多25个字符 |
| Mapper地址 | 输入 Map任务可执行命令或脚本的存储路径,如使用KS3存储它们,该路径值的形式应该是: ks3://BucketName/path/MaperExecutable |
| Reducer地址 | 输入 Reduce任务可执行文件或脚本的存储路径,如使用KS3存储它们,该路径值的形式应该是: ks3://BucketName/path/ReducerExecutable |
| 输入地址 | 指定原始数据的存放位置,这个地址必须已经存在,并且您有权限读取这个地址的文件。 |
| 输出地址 | 指定计算结果存放位置,这个地址必须是不存在的,并且您有权限对这个地址进行写操作,否则作业运行会失败。 |
| 失败后操作 | 当作业执行失败后,集群可以根据这里的设置自动执行一些操作 继续:作业执行失败后,继续执行下一个作业。 取消作业并等待:作业执行失败后,取消集群中已提交的作业,集群进入等待状态,直到提交下一个作业。 销毁集群:作业运行失败后,销毁集群。 该选项的结果不会受到“集群释放保护”功能影响 |
| 参数 | 除了以上几个streaming program作业必须输入的参数外,若您还可以为作业设置其他参数,请在参数输入框中以空格为分隔符输入参数配置。输入参数时,只需要输入参数本身字符串即可,用空格分隔,无需参数转义和url encode。 |
3.如果您是在创建集群阶段添加作业,点击“下一步”,跳转到确认订单页面,提交订单后,添加的作业会在集群创建完成后开始执行。
4.如果您是对已创建的集群添加作业,作业提交后立即开始执行。
3.添加Hive作业
Hive 是一种开源数据仓库和分析套件,它在 Hadoop 的基础上运行。Hive 脚本使用类似 SQL 的语言,名为 Hive QL(查询语言),该语言会将SQL语法映射为MapReduce 编程模型,支持典型的数据仓库查询交互。Hive 可避免您以低级别的计算机语言(如 Java)编写 MapReduce 程序这样的复杂工作。KMR提供对Hive的支持。
1.在KMR集群创建时或者创建完成后打开添加作业页面,前置步骤请参考集群创建和集群操作中的作业详情部分
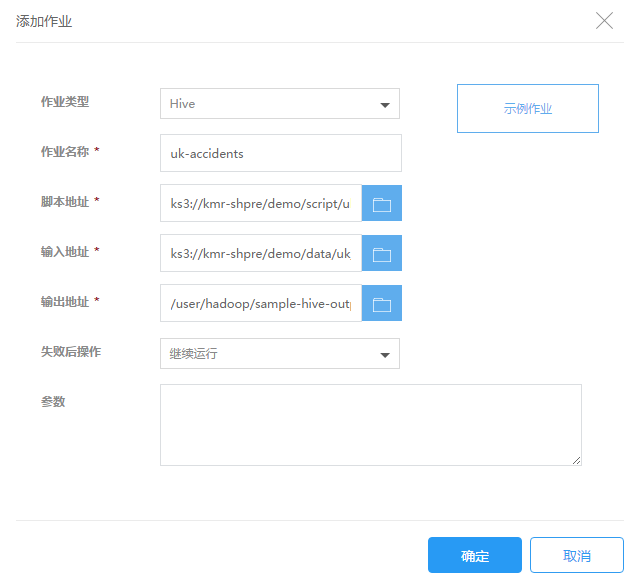
2.在添加作业页面填写作业信息,点击确定提交:
| 字段 | 操作 |
|---|---|
| 作业类型 | 选择需要执行的作业类型,这里请选择Hive |
| 作业名称 | 输入作业名称,长度最多25个字符 |
| 脚本地址 | 输入Hive脚本的存储路径,如使用KS3存储它们,该路径值的形式应该是: ks3://BucketName/path/HiveScript。 |
| 输入地址 | 指定原始数据的存放位置,这个地址必须已经存在,并且您有权限读取这个地址的文件。 |
| 输出地址 | 指定计算结果存放位置,这个地址必须是不存在的,并且您有权限对这个地址进行写操作,否则作业运行会失败。 |
| 失败后操作 | 当作业执行失败后,集群可以根据这里的设置自动执行一些操作 继续:作业执行失败后,继续执行下一个作业。 取消作业并等待:作业执行失败后,取消集群中已提交的作业,集群进入等待状态,直到提交下一个作业。 销毁集群:作业运行失败后,销毁集群。 该选项的结果不会受到“集群释放保护”功能影响 |
| 参数 | 输入参数。只接受两种参数类型,分别是--hiveconf key=value 和 --hivevar key=value。前一种参数是用来覆盖hive执行时的配置。后一种参数是用来声明自定义的变量,可以在脚本中通过${KEY}来引用。输入参数时,只需要输入参数本身字符串即可,用空格分隔,无需参数转义和url encode。 |
3.如果您是在创建集群阶段添加作业,点击“下一步”,跳转到确认订单页面,提交订单后,添加的作业会在集群创建完成后开始执行。
4.如果您是对已创建的集群添加作业,作业提交后立即开始执行。
4.添加Pig作业
Pig 是一种开源 Apache 库,在 Hadoop 的顶层上运行。该库使用名为 Pig Latin 的语言编写的、类似 SQL的命令,并将这些命令转换到 MapReduce 任务中。KMR支持 Apache Pig,此编程框架可用于分析和转换大型数据集。有关 Pig 的详细信息,请转到 http://pig.apache.org/
1.在KMR集群创建时或者创建完成后打开添加作业页面,前置步骤请参考集群创建和集群操作中的作业详情部分
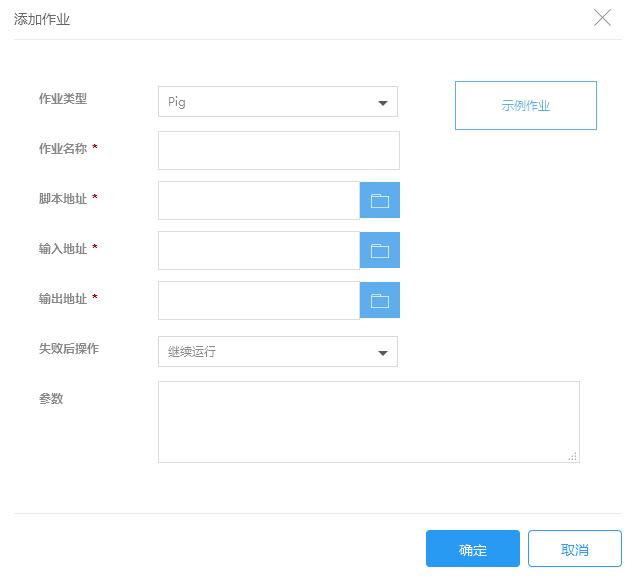
2.在添加作业页面填写作业信息,点击确定提交:
| 字段 | 操作 |
|---|---|
| 作业类型 | 选择需要执行的作业类型,这里请选择Pig |
| 作业名称 | 输入作业名称,长度最多25个字符 |
| 脚本地址 | 输入pig脚本的存储路径,如使用KS3存储它们,该路径值的形式应该是: ks3://BucketName/path/PigScript |
| 输入地址 | 指定原始数据的存放位置,这个地址必须已经存在,并且您有权限读取这个地址的文件。 |
| 输出地址 | 指定计算结果存放位置,这个地址必须是不存在的,并且您有权限对这个地址进行写操作,否则作业运行会失败。 |
| 失败后操作 | 当作业执行失败后,集群可以根据这里的设置自动执行一些操作 继续:作业执行失败后,继续执行下一个作业。 取消作业并等待:作业执行失败后,取消集群中已提交的作业,集群进入等待状态,直到提交下一个作业。 销毁集群:作业运行失败后,销毁集群。 该选项的结果不会受到“集群释放保护”功能影响 |
| 参数 | 参数:输入以下指定的参数进行相关的配置:-D key=value指定配置,-p KEY=VALUE指定变量,也可加入自定义参数。输入参数时,只需要输入参数本身字符串即可,用空格分隔,无需参数转义和url encode。 |
3.如果您是在创建集群阶段添加作业,点击“下一步”,跳转到确认订单页面,提交订单后,添加的作业会在集群创建完成后开始执行。
4.如果您是对已创建的集群添加作业,作业提交后立即开始执行。
4.添加spark作业
Spark是一种类Hadoop MapReduce的通用并行框架,Spark拥有Hadoop MapReduce所具有的优点,同时具有SQL查询,流式计算,集群学习等模块,得到了广泛的认可。KMR集成了最新版本的Spark,可用来构建大型的、低延迟的数据分析应用。
1.在KMR集群创建时或者创建完成后打开添加作业页面,前置步骤请参考集群创建和集群操作中的作业详情部分
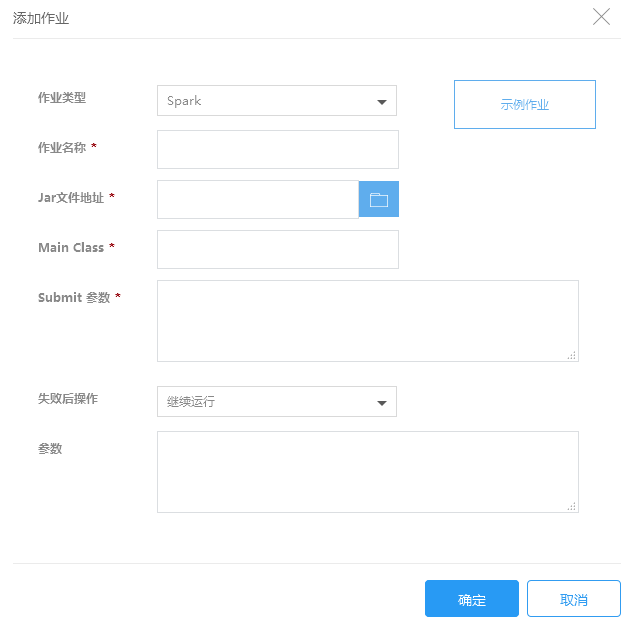
2.在添加作业页面填写作业信息,点击确定提交:
| 字段 | 操作 |
|---|---|
| 作业类型 | 选择需要执行的作业类型,这里请选择Spark |
| 作业名称 | 输入作业名称,长度最多25个字符 |
| Jar文件地址 | 输入Spark应用程序的存储路径,如使用KS3存储它们,该路径值的形式应该是 ks3://BucketName/path/SparkJar |
| MainClass | 指定主程序的类名 |
| Spark-submit选项 | 输入spark-submit选项 详情请参考 https://spark.apache.org/docs/1.5.2/submitting-applications.html |
| 失败后操作 | 当作业执行失败后,集群可以根据这里的设置自动执行一些操作 继续:作业执行失败后,继续执行下一个作业。 取消作业并等待:作业执行失败后,取消集群中已提交的作业,集群进入等待状态,直到提交下一个作业。 销毁集群:作业运行失败后,销毁集群。 该选项的结果不会受到“集群释放保护”功能影响 |
| 参数 | 当对以下的参数进行多次设置时,只有最后一次设置才会生效: --name、--driver-memory、--driver-java-options、--driver-library-path、--driver-class-path、--executor-memory、--executor-cores、--queue、--num-executors、--properties-file、--jars、--files、--archives。 不可以指定的参数有: --master、--deploy-mode、--py-files、--driver-cores、--total-executor-cores、--supervise、--help。 • 对于不可以指定的参数,若指定也不会报错,只是是参数设置无效。 • 对于CORE节点为一般通用型集群或测试体验版集群,在设置参数时,--driver-memory和--executor-memory建议设置为小于1G,否则可能会因为集群资源不足,影响作业正常运行。 • 对于CORE节点为上述以外的其他类型时,--driver-memory和--executor-memory建议设置为小于2G,否则可能会因为集群资源不足,影响作业正常运行。 您输入参数时,只需要输入参数本身字符串即可,用空格分隔,无需参数转义和url encode。 |
3.如果您是在创建集群阶段添加作业,点击“下一步”,跳转到确认订单页面,提交订单后,添加的作业会在集群创建完成后开始执行。
4.如果您是对已创建的集群添加作业,作业提交后立即开始执行。