文档中心
产品功能
KMR提供了丰富的管理功能和便捷的程序开发接口,使您可以高效自动化的进行数据处理和分析工作,节省管理成本和使用成本:
弹性扩展
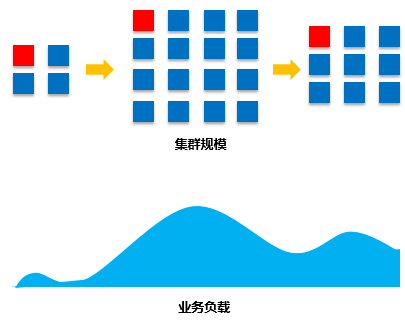
KMR集群具备良好的横向扩展能力,您可以根据业务需求弹性的增加或者减少节点,适应多变的业务场景,节省集群使用成本。
集群主节点和元数据高可用
除了基础的服务可用性和数据可靠性保障外,KMR提供了主节点和元数据高可用功能来进一步保证集群持久对外提供服务:
- 采用两个主节点作为集群管理节点,担当NameNode、ResourceManager、HbaesMaster等角色,当节点宕机时,监控系统会自动发现,由另一节点接管服务,并自动启动新的主节点使集群恢复到稳定状态。
- 一些集群服务依赖RDBMS作为元数据库,当元数据丢失时,集群无法正常工作,KMR支持使用RDS实例作为元数据库,可以有效的提升元数据的可靠性和读写性能。
注意:主节点和元数据高可用功能仅适用于常驻集群。
标准存储服务(KS3)访问
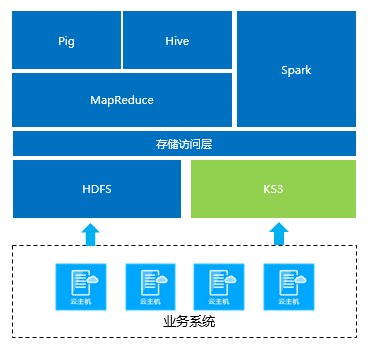
KMR可以通过内部高速网络直接访问标准存储服务(KS3),在进行数据处理工作时,您可以首先把原始数据汇总到KS3。KMR集群中运行的MapReduce、Hive、Pig、Spark等作业可以直接调用KS3中存储的这些数据进行计算,并把结果写回到KS3。KS3提供了较低使用成本和极高的数据可靠性,并保证在集群释放时仍然可以持久的存储原始数据和计算结果。
Hadoop生态集成

KMR除集成了基础的Hadoop组件外,同时集成了Spark, Hbase, Storm, Kafka等生态组件,以及Ambari,Ganglia等集群监控管理工具,帮助您轻松构建复杂的大数据分析系统,满足批量计算、流式处理、消息队列、交互式查询、NoSQL等多种业务场景的需求。
集群模板和执行计划
集群模板记录了创建一个集群所需的配置信息以及集群中需要运行作业的配置信息,模板功能帮助您快速创建一个特定配置的KMR集群,或者完成一组作业,您可以新建或通过已有集群来生成模板。
集群执行计划可以帮助您自动化的完成一组计算作业,您需要指定一个集群模板来创建执行,一次性或周期性地自动启动集群,完成计算作业,并在结束后释放集群资源。您可以自定义执行频率、计划开始时间、结束时间,按需使用集群资源,实现自动化的大数据分析。
计算作业管理
KMR可以支持MapReduce, Spark, Pig, Hive等多种计算作业,这些计算可通过Hue的控制面板进行管理,详情请查看Hue
API & SDK
KMR提供了用于集群操作的OpenAPI和SDK,您可以根据需要开发应用程序,实现集群创建、释放,作业下发,集群和作业状态监控等多种自动化任务,进一步提高效率,降低成本。